
The Emergence of Continuous Trial Models
The design of clinical trials is shifting from “one-off” to continuous, or “always-on,” trials. This shift is made possible by the adoption of a range of decentralized clinical trial technologies, real-time data capture, and adaptive trial designs, which encourage flexible models of research. The goal of continuous trials is to offer the potential for continuous data collection, hypothesis generation, and data analysis, and hence the generation of new evidence over time.
Instead of having temporal bounds in traditional trials such as the start date and end date, continuous trials allow for the recruitment of additional patients, enlargement of cohorts, and decision-making in a timely manner. This presents significant challenges for clinical data management (CDM) in relation to standards, monitoring, and regulatory and oversight activities. The shift to continuous model inverts established CDM practices of data collection, verification, and reviewing.
Structural Differences from Traditional Trial Models
The traditional clinical trial process is a batch process that proceeds from study start-up, recruitment, and treatment of patients to study end and final analyses. Data management processes are also closely tied to this, concentrating on periodic data cleanings, milestone reviews, and batch data submissions. This model is based on incremental and batch-wise data collection and management.
In continuous trials, however, studies remain open with no set timeframes for recruitment. The ability to modify or change the protocol if needed, based on interim data and analyses, is essential, facilitating adaptive designs. Data are gathered continually from different sources, including electronic health records (EHRs), wearables, and remote monitoring (dynamic data). Rather than permanently locking the data once data collection has stopped and performing analyses, interim analyses are performed while data are being collected. This changes not only the perspective of static data and time- or process-based reviews of CDM processes, but also the way data are captured, validated, reconciled, and monitored throughout the study lifecycle.
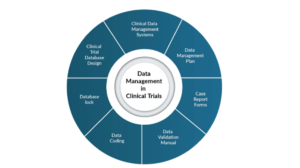
The figure below illustrates the centrally involved components of data management, such as clinical trial database design, case report forms, the data management plan, data validation manual, database lock, data coding, and the clinical data management system, showing how they are interrelated in a clinical trial.
Implications for Data Capture, Review, and Monitoring
Embracing continuous trial models requires a shift to continuous data operations as opposed to periodic operations, which challenges the traditional concept of data capture, review, and monitoring, essentially changing how data are captured and monitored. The data capturing methodologies are modified to counter the streaming data architecture and not the data uploads, to support the real-time intake of high-frequency data from the various data sources. This can encompass actual-life data and patient-generated health data, which introduces more variability. Data validation should also be done at the point of entry to identify and correct errors and issues in real time, as opposed to post hoc, to maintain the quality of data.
The timelines of data review also vary in continuous trials. Regular cleaning operations of data are substituted by data surveillance, with automated edits and data anomaly surveillance. Reconciliation, being performed periodically, becomes continuous in systems used for electronic data capture (EDC) systems, laboratory functions, and image databases, among others. Surveillance plans also evolve, where risk-based monitoring is stretched to real-time risk assessment abilities, using centralized dashboards and data feeds, fewer required checks of source data, and more active risk detection.
Such dynamics imply that CDM systems will have to transform into on-demand 24/7 systems capable of handling large data feed volumes, ingestions, and validations and withstanding stringent data security and integrity levels.
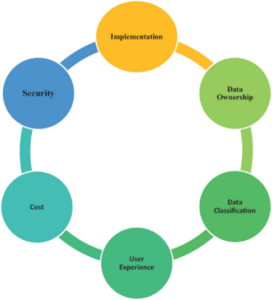
The figure below illustrates important factors in implementing a data management strategy, such as security, data ownership, data classification, user experience, cost, and implementation, and their relationships in building a secure, effective data system.
The Need for Stronger Standards, Interoperability, and Governance
As clinical data systems continue to evolve to provide continuous data flows and integrate with ecosystems, the value of robust data standards increases, as well. Standards bodies like the Clinical Data Interchange Standards Consortium, have structured data models that are central to offering consistency and harmonization to dynamic data. Aggregate data notations and controlled terminologies are essential in assuring a significant semantic consistency in the ongoing development and expansion of data.
Interoperability and data exchange also contribute significantly toward the seamless integration of EDC systems, EHRs, and external data systems. Fast Healthcare and Interoperability Resources and other modeling suggest the capability of interconnecting live streams of data via interoperable application programming interfaces and data exchange criteria. These standards should ensure speedy transmission of data at high velocity with minimal latency, loss, and transformation of data.
Trials of a continuous nature must also be accommodated in terms of their models of governance. These models should feature a method of metadata and automated validation that checks regulatory compliance in real time. Failure to adopt these governance frameworks introduces possible risks for data inconsistencies, poor data quality, and low data adherence.
Regulatory and Sponsor Oversight Models
Even regulatory landscapes are starting to address the emerging needs of the continuous models. New models assist in adapting designs and real-time monitoring of data used by regulatory bodies such as the U.S. Food and Drug Administration and European Medicines Agency. This is indicative of the realization that current regulatory measures are not necessarily the best in managing dynamic and constantly expanding data.
A key change related to study-end submissions allows continuous data access and analyses, instead of having the whole dataset locked up and reviewed only at the end of the study. In this scenario, regulators have constant access to real-time dashboards and audit logs to assess data and compliance. Moreover, protocol management is opened to permit iterative changes according to emerging evidence without compromising regulatory requirements.
In order to accommodate such expectations, sponsors must construct the infrastructure in ways that enable transparency, traceability, and heightened responsiveness. This involves establishing mechanisms to report on the conduct and the quality of data used in the study in real time and to facilitate regulatory compliance.
Impacts on CDM Teams and Vendors
Continuous trials introduce significant flexibility to the work processes of CDM teams and vendors. The CDM groups have less to do with “cleaning” data and more to do with data choreography. This involves an in-depth knowledge of data integration, standards, and deployment of analytics and automation tools. One such skill is real-time data monitoring and responsiveness to problems.
In the case of vendors, the focus is on developing a cloud-based solution that is scalable, resilient, and capable of running at any point in time. These platforms must incorporate machine learning processes to identify anomalies and perform predictive quality control to offer the possibility of proactive management of data risks. The use of modular system designs to facilitate quick system changes to accommodate protocol and study amendments is another important aspect.
This development makes CDM not an operationally based role, but a strategic priority role in clinical research, with the emphasis being placed on generation of quality data in a timely manner to make ongoing decisions.
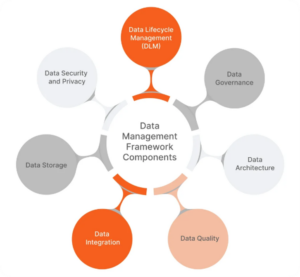
The figure below illustrates the key components of a data management framework, including data lifecycle management, data security and privacy, data governance, data architecture, data storage, data integration, and data quality, highlighting their interconnected roles in effective data management.
Conclusion: Preparing CDM for Dynamic Trial Architectures
Continuous trials introduce a new paradigm for clinical development and demand a holistic rethink of data standards, governance, and workflows. The key to the success of such models is the maintenance of the integrity of datasets and data compliance with ever-changing datasets, which is best executed in real time.
To capitalize on the advantages of new trial designs, investments in continuous data platforms, development of standardized, interoperable data models, and flexible governance frameworks are required. In this context, clinical data management tools will reach beyond their conventional capabilities to serve as the driving force of sustained learning and empower agile decision-making in the clinical development arena.
Contributed by Shashidar Reddy Abbidi, MS, PMP, a Senior Manager in Clinical Data Management at Bristol Myers Squibb with more than nine years of experience leading data-driven strategies for clinical trials and advancing healthcare research. An active research paper and trade article author, he is a coauthor of a forthcoming piece on “Implementation of AI for Future Clinical Data Review” and volunteer editorial advisor for ACRP’s peer-reviewed Clinical Researcher journal.


