
Clinical Researcher—June 2026 (Volume 40, Issue 3)
PEER REVIEWED
Shashidar Reddy Abbidi, MS, PMP; Nishitha Gali, MHA
Data management involves a review of clinical data, which is the step-traceable process of detecting, capturing, and fixing data issues prior to analysis and submitting to the regulation. It cuts across edit checks, list reviews, adverse event/serious adverse event (AE/SAE) reports, lab reconciliation, medical coding supervision, and protocol deviation reviews, as well as risk-based quality management (RBQM) signal monitoring utilizing key risk indicators (KRIs) and quality tolerance limits (QTLs).
Quantified workload demonstrates the need to hasten automation: a Journal for Clinical Studies analysis reported an average clinical trial required 21,104 queries, 7,560 (36%) of which were manual, calculating an operational cost of approximately €150 per manual query. In that article, the authors presented these inefficiencies as trial risks whose mitigation can lead to faster data review and database lock with cleaner data being attained for critical studies.{1} It also reported that one in four regulatory applications for studies must be resubmitted, and a preliminary refusal can add to eventual approval by a median of 435 days.
Artificial intelligence (AI)-enabled review is not feasible in situations where models are not trained on protocol and objective-driven paths; where drift monitoring and retraining are absent as new locations, vendors, and amendments generate changes in data distributions; where auditability is weak; and when AI that is not crowd-generated or change-controlled is employed. The outcomes of such lapses are query noises, gauged anomalies, and varying and unstable justifications, which might prove difficult to replicate at the inspection phase.
Further, generative components can reuse guidance between cycles, and discriminative models can be more inaccurate and forgetful over time, posing the risk of late rework and slowing down the database lock.{2} Versioned prompts and regression tests, or prompts cemented with evidence outputs, are needed to stop uncontrolled behavior and maintain entire audit trails.
The objectives of our overall study, of which this literature review is just the introduction, are to:
- Design a practical AI architecture for clinical data review spanning natural language processing (NLP), discriminative AI, anomaly detection, generative AI (GenAI), and feedback learning.
- Specify a measurement framework (precision/recall, query acceptance rate, cycle-time reduction, and drift metrics).
- Propose governance and a data management–AI interface team to translate protocols into testable AI directives and manage validation.
The research covers the procedures of sponsor and contract research organization (CRO) data management operations, RBQM and centralized monitoring, integration with electronic data capture (EDC) and vendor feeds for electronic clinical outcome assessments/electronic patient-reported outcomes (eCOAs/ePROs), ePRO laboratories, and ePro safety systems. It excludes artificial general intelligence (AGI)-level autonomy, and recognizes that future of clinical data review is an intermediate between AI-enhanced repetitive checks and triage and qualified examiners judging anomalies and holding them responsible. Integration into the review plans and exception workflows is the deliverable, rather than independent data edits in production EDC.
To achieve our objectives, the study has several parts. In this first part, a literature review summarizes findings about AI techniques, statistical surveillance, and the regulation of clinical data review. It compares GenAI, NLP, discriminatory models, and anomaly detection with reinforcement learning and outlines the purposes of validation and regulation.
In a proposed Part II, a methods and techniques section would explain the uses of end-to-end implementation design: the data pipelines, feature engineering, model design, human-in-the-loop processes, validation protocols, and monitoring drift. Part II would also include an experiments and results report offering technical performance and operating impact in the shape of a measured scope of precision, recall, cycle period, and query acknowledgment. The implications of trade-offs, limitations, and compliance would be interpreted in Part II’s discussion section, with the study concluding by offering future research recommendations and a summary of the research. The structure assists in giving a descriptive account for moving from problem formulation to a practical implementation recommendation account.
Literature Review
Information Sources
The literature search was conducted using PubMed/MEDLINE to capture clinical trial monitoring, RBQM, data quality, and health-informatics studies; Scopus to provide cross-disciplinary coverage spanning clinical research, informatics, and AI; Google Scholar to broaden retrieval of applied implementation reports and highly cited sources; and IEEE Xplore to capture relevant methods and governance concepts from engineering domains, including verification, regression testing, and machine learning (ML) lifecycle management. To ensure alignment with regulated clinical trial practice, targeted searches were also conducted on authoritative guideline and regulatory repositories, including the International Council for Harmonization (ICH) database for Good Clinical Practice (GCP) guidance and the U.S. Food and Drug Administration (FDA) repository for AI/ML lifecycle and validation discussions in drug development.{3} Consortium and industry sources relevant to RBQM and centralized monitoring were included when they provided traceable descriptions of operational approaches or measurable implementation benchmarks.
Search Terms
Search terms combined clinical trial operations and data management concepts with AI, analytics, and lifecycle governance terminology. Key terms included clinical data review, clinical data management, risk-based quality management (RBQM), risk-based monitoring (RBM), source data verification (SDV), source data review (SDR), centralized monitoring, key risk indicators (KRIs), quality tolerance limits (QTLs), anomaly detection in clinical trials, natural language processing (NLP) in clinical trials, generative AI (GenAI) in data management, model drift and concept drift, population stability index (PSI), validation under GCP, and AI/ML lifecycle management. Search strings were adapted to database syntax and refined iteratively by screening titles and abstracts to improve relevance.
Eligibility Criteria
Studies were included when they were peer-reviewed journal articles or full-text conference papers with sufficient methodological detail, regulatory or standards-based documents, or consortium publications directly relevant to RBQM, centralized monitoring, and clinical data review governance. High-quality industry case studies were included when they reported measurable outcomes or implementation details that could be used as feasibility benchmarks, with the understanding that such results are not automatically generalizable across all sponsor and CRO contexts. Eligible sources were limited to English language publications and were required to focus on human clinical trials or clinical trial operations. Studies were excluded when they were abstract-only outputs without full methods, non-English publications, opinion pieces without verifiable evidence, or materials unrelated to clinical trials, data management, RBQM, or regulated AI lifecycle management. Evidence from other high-stakes regulated engineering domains was used selectively when it directly informed validation practices applicable to clinical trial AI governance, such as requirements traceability and regression testing under change control.
Screening and Synthesis
Titles and abstracts were screened to identify relevance to four themes: RBQM and centralized monitoring; statistical monitoring and anomaly detection; NLP and GenAI applications in data management workflows; and regulatory expectations, validation, and lifecycle governance. Full texts were reviewed when accessible and synthesized using a thematic approach, emphasizing how methods map to operational workflows and governance requirements. Findings were integrated into a conceptual implementation framework focused on protocol alignment, auditability, controlled change, drift monitoring, and human oversight.
Clinical Data Review Today: RBQM, SDV/SDR, and Central Monitoring
A review of the literature finds that modern clinical data review has moved increasingly toward risk-based approaches, in which monitoring and updating projects prioritize the data and processes most inclined to influence participant safety and primary endpoint validation. RBQM and associated RBM monitoring practices are appropriate in this environment in that such oversight targets critical information and high-risk operations instead of using equal scrutiny across locations, participants, and variables.{4} In this model, SDV and SDR are still applicable, but with increased selectiveness and are often driven by more centrally generated signals and risk indicators than general, routine verifications.
This shift in the operation is often characterized by a people-process-technology paradigm. Within this framework, trained clinical reviewers (people) implement defined review plans and escalation paths (process) on top of integrated data infrastructure, analytics dashboard, and audited workflow (technology). Among the technology requirements are data-consolidation between EDC systems and outside vendors, periodic refresh cycles that facilitate prompt centralized review, rule logic degree of transparency connected to traceability, and governance-consistent access controls.{5} This literature highlights how the efficacy of RBQM is reliant upon the functionality of these three elements when they are jointly connected so as to permit uniform, scalable, and reviewable practices.
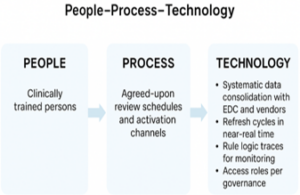
The figure above demonstrates how, under the coordinated efforts of people, process, and technology, central monitoring is operationalized by risk-based clinical data review. Clinically trained reviewers determine oversight priorities, interpretation of centrally derived signals, and exceptions adjustment. Standard processes are capable of transforming the protocol risks into the review schedules, escalation routes, and recorded decision processes to guide the SDV/SDR targeting.{6} Enabling technology pools EDC and the feeds of external vendors, updates data regularly, and supports the requirements of governance expectations. The three components form a closed loop, which enables scaling data review on a consistent basis and inspection-ready data review. This saves on rework and concentrates on the riskiest data.
Statistical Monitoring and Anomaly Detection in Trials
The concept of centralized monitoring critically depends on statistical surveillance, since it offers objective ways of detecting trends which are not supposed to be present according to the standard clinical or operational distribution. Common traditional methods are z-scores and robust z-scores (e.g., normalizing with median absolute deviation) to identify univariate outliers (e.g., extreme values or implausible change-from-baseline trends). Also, multivariate viewpoints are applied to analyze abnormal combinations of correlated variables (e.g., laboratory panels, visit timing patterns, and vital sign paths). The literature tends to point out control charts, like CUSUM or EWMA, as a useful tool which can be used to identify gradual changes over a period of time instead of just suddenly displaced data.{7}
These foundational methods naturally extend to contemporary unsupervised and semi-supervised anomaly detection methods, such as Isolation Forest, One-Class SVM, and autoencoder reconstruction error, which gain knowledge of desired structure and identify observations that are unlikely to follow desired structure. Previous research explains the ability of such methods to assist site-level risk detection by detecting abnormal digit preference, implausibly regular measurements, abnormal dispersion in visit timing, or abnormal AE/SAE rates.
One of the most dominant examples provided in the literature on RBM is the ability of TransCelerate to demonstrate scalable statistical monitoring of a COPD dataset with 178 sites and 1,554 participants, indicating possible applicability within a multi-scale setting. In addition to clinical trials, similar monitoring requirements are also suggested in the wider analytics literature (e.g., supply chain risk modeling), which supports the significance of monitoring in a dynamic environment and the applicability of drift-aware monitoring.{8}
NLP and Generative AI in Data Management: From Instructions to Queries
At least a large part of clinical data management entries such as protocols, data review plans, codes of conduct, histories of discrepancies, and narrative fields are in unstructured or semi-structured text formats. This has led to more references in literature to NLP as a convenient means of mining structured information out of such sources to facilitate a consistent operation of extraction requirement of a review.{9} NLP uses outlined in the fields of healthcare and trial processes involve entity recognition (e.g., AE-related words, comorbid drugs, visit names), mapping onto controlled vocabularies, and relation extraction (e.g., establishing a connection between treatments and events or events and time) to express narrative constraints as machine-testable logic. The studies of the clinical coding automation also affirm that the language-based approach can be effective in standardizing the terminologies and minimizing the variability in manual processing.{10}
Moreover, research findings are presented in which Latent Dirichlet Allocation is a topic modeling method used to group recurrent query themes, common drivers of data-quality, and targeted operational interventions as part of continuous review processes.{1} The literature characterizes generative AI as having a potential further extension of NLP capabilities, i.e. drafting standard query text, summarizing anomaly context and generating structured review notes. Nevertheless, published discourse warnings also state that generative algorithms can introduce variability, unfounded logic, or illusory data when a set of output is not limited and linked to evidence.{11} The broader argument that automation can improve the routing time and lessen the repetition of the workload is even further justified by related healthcare operations research, including the assessment of the AI-assisted call center automation.
Regulatory and Validation Expectations for AI-Enabled Trial Processes
More and more of the literature features the context of AI-powered trial procedures by applying the concepts of transparency, lifecycle management, and acceptance-proven suitability. The ICH E6(R3) guideline for GCP focuses on the risk-based quality approach and delegates quality systems protecting the participants and guaranteeing data integrity the principles that remain applicable in AI-backed review systems. In this arena, systems must be established with well-defined roles and procedures, records that are documented, traceable, and auditable—just as is expected when following GCPs.{12} Likewise, FDA discussions about AI/ML in the context of drug and biological products development emphasize lifecycle aspects, including how to define context of use, evaluate credibility, document model performance, and control updates as needed.{13}
Other examples of emerging cases in which regulators have accepted AI tools within a defined range are noted in the literature, including FDA qualification of an AI-related drug development tool to be used during MASH clinical trials, implying viability when roles and governance demarcations are clear.{14} Comparisons are also made to verification practices in other safety-critical domains, where structured verification plans, regression testing and requirements- traceability are considered as indispensable -practices that can be applied to AI-enabled clinical review under change containment.{15}
The figure above outlines regulatory and validation expectations in the implementation of AI in the process of conducting a clinical trial. It relates three compliance pillars, which are transparency, control, and provable appropriateness. Transparency entails RGQM and evidence-based reproducible products that are in line with GCP. Control deals with lifecycle control that has a defined context of use, versioned models and prompts, regression testing, and change control, so that updates can be inspected. Provable appropriateness is concerned with validating and justifying the use of AI tools in making specific decisions in a way that would allow us to trace the requirements made to test evidence of safety-important engineering. These pillars combined necessitate human management, auditable logs, and constant monitoring to control drift, as well as avoid uneven behavior of the reviewers.
Identified Gaps: Governance, Model Degradation, and Workflow Fit
Nevertheless, the literature indicates tense and unresolved gaps in governance and operational fit in spite of increasing methodological maturity. First, standardized, machine-readable objectives do not usually encode protocol intent, and it is not always clear how narrative protocol requirements can be properly converted into quantified review rules and acceptance standards.
Second, there is often underdeveloped drift monitoring and lifecycle. Alterations in site mix, patient populations, vendor feeds, dictionaries, and protocol updates may change the distributions of data, negatively affect model performance, leading to conditions of false positives, false suppressions, or alterations in the alerting pattern over time. These impacts are highlighted when formulating concerns about model degradation, as performance is not fixed in changing operational conditions.
Third, a repetitive issue is workflow integration. The literature indicates that successful implementation must have an effective interface among clinical data management and technical personnel to convert protocol requirements into verifiable logic, validate cases, and align model outputs with the plans for operational review. Pragmatic RBM advice emphasizes that centralized monitoring efficacy is based on not just analytics aptitude but competent positions, explicit administration, and cross-functional collaboration, distinct operational governance, and technical interoperability unlike making analytics a distinct undertaking.{16}
References
- Bradford J, Aird S. 2021. Querying the queries – An AI approach to manage clinical data quality. Journal for Clinical Studies 13(6):40–1. https://journalforclinicalstudies.com/wp-content/uploads/2021/12/Querying-the-Queries-%E2%80%93-An-AI-Approach-to-Manage-Clinical-Data-Quality.pdf
- Savela, IS. 2025. Generative AI & the Right to Erasure: Can GDPR’s ‘Right to Be Forgotten’ Delete AI Outputs? (Master’s thesis, Lund University). Lund University Publications Student Papers. https://lup.lub.lu.se/student-papers/record/9204199
- Hansen J, Ahern S, Earnest A. 2023. Evaluations of statistical methods for outlier detection when benchmarking in clinical registries: a systematic review. BMJ Open 13(7):e069130.
- Verma V, Mishra A, Gowrav MP, Nischitha MS. 2023. Clinical Trial Monitoring: An Overview of Risk-based Approach. J Young Pharm 15(2):239–44.
- Barnes S, Katta N, Sanford N, Staigers T, Verish T. 2014. Technology considerations to enable the risk-based monitoring methodology. Therapeutic Innovation & Regulatory Science 48(5):536–45. https://link.springer.com/content/pdf/10.1177/2168479014546336.pdf
- Ezeanochie C, Akomolafe OO, Adeyemi C. 2023. Operational Leadership in Managing Complex, Multi-Country Oncology Clinical Trials. International Journal of Clinical Trial Operations & Management 11(2):142–56.
- Nisa G, Abdelwahab MM, Sanaullah A, Maqsood M, Abdelkawy MA, Hasaballah MM. 2025. Development of an Efficient CUSUM Control Chart for Monitoring the Scale Parameter of the Inverse Maxwell Distribution in Asymmetric, Non-Normal Process Monitoring with Industrial Applications. Symmetry 17(11):1819.
- Vishwakarma SK. 2025. AI-driven predictive risk modelling for aerospace supply chains. International Journal of Innovation in Business & Economics and Applied Journal. https://www.iibajournal.org/index.php/iibeaj/article/view/64
- Ahmed U, Iqbal K, Aoun M, Khan G. 2023. Natural language processing for clinical decision support systems: a review of recent advances in healthcare. J Intell Connect Emerg Technol 8(2):1–17.
- Almarshadi NF, Alharbi MMA, Alharbi MS, Alwaked WA, Alsayer HM, Alhussain SM. 2024. Clinical and Medical Coding: A New Pathway for Automation-An Updated Review. Journal of Medical and Life Science 6(4):633–51.
- Rangu S. 2025. Analyzing the impact of AI-powered call center automation on operational efficiency in healthcare. JISEM Journal. https://www.jisem-journal.com/index.php/journal/article/view/8901
- International Council for Harmonization of Technical Requirements for Pharmaceuticals for Human Use. 2025. ICH Harmonized Guideline: Guideline for Good Clinical Practice E6(R3). https://database.ich.org/sites/default/files/ICH_E6%28R3%29_Step4_FinalGuideline_2025_0106.pdf
- U.S. Food and Drug Administration. 2023. Using Artificial Intelligence & Machine Learning in the Development of Drug & Biological Products: Discussion Paper and Request for Feedback (revised February 2025). https://www.fda.gov/media/167973/download
- U.S. Food and Drug Administration. 2025. FDA qualifies first AI drug development tool, will be used in “MASH” clinical trials. https://www.fda.gov/drugs/drug-safety-and-availability/fda-qualifies-first-ai-drug-development-tool-will-be-used-mash-clinical-trials
- Nagaraj V. 2025. Ensuring low-power design verification in semiconductor architectures. JISEM Journal. https://www.jisem-journal.com/index.php/journal/article/view/8903
- CluePoints. 2016. CluePoints answers your risk-based monitoring implementation questions. https://cluepoints.com/cluepoints-answers-your-risk-based-monitoring-implementation-questions/

Shashidar Reddy Abbidi, MS, PMP, (asreddy.cdm@gmail.com) is Senior Manager, Clinical Data Management, Bristol-Myers Squibb, and an Editorial Advisor for ACRP’s Clinical Researcher journal.
Nishitha Gali, MHA, is an Independent Researcher.


