
Clinical Researcher—June 2019 (Volume 33, Issue 6)
DATA-TECH CONNECT
Richard Young
According to Tufts Center for the Study of Drug Development (CSDD), the average time to build and release a clinical study database is more than 73 days and the average time to lock data at the end of a trial is nearly 39 days{1}; combined, this is more than five days longer than it was 15 years ago.{2} With increasingly complex clinical studies, the industry can’t afford to go backwards. Study delays slow treatments to patients and can cost $1 million to $13 million dollars a day.{3}
In 2017, one pharmaceutical company* began addressing this issue head-on by setting aggressive internal targets despite already outperforming industry averages for most data management cycle times. This company implemented innovative processes and technology to tackle tough data challenges, such as reducing sites’ data entry turnaround times, integrating external data sources, gaining buy-in from internal departments for timely data reviews, and reducing the lengthy rounds of user acceptance testing (UAT). The company has since reduced database build and release times from 12 to 14 weeks to six to eight, and data lock times from 22 days to just 15.
More Data, More Sources, More Stakeholders
The growing complexity of clinical trials has complicated data management processes in various ways. First, there is a greater volume of data in clinical trials. Overall, the number of datapoints has nearly doubled, from 494,236 in trials between 2001 and 2005 to 929,203 in trials between 2011 and 2015.{4} Sponsors and contract research organizations (CROs) report that handling today’s high volume of data is one of the biggest challenges with data management.{1}
In addition to increased data volume, the number of data sources—including digital sources and wearable devices—is growing. According to Tufts CSDD, the average number of data sources used in clinical trials will increase from four to six in just three years.{4}
For many organizations, a third complication impacting data management is the number of stakeholders involved. In 2019, about half of all clinical trials are outsourced to CROs—often more than one CRO per trial—and each has its own data management methods and technologies. Most sponsor and CRO systems are disconnected from each other; therefore, sponsors lack direct access to their data and are dependent on periodic data transfers from their CROs. With each additional source, data cleaning and access become more complicated. Internal stakeholders including safety, medical, and statistics, also need to review the data, further raising the stakes on securing timely access to the data.
Smarter Ways to Speed Database Build
The pharmaceutical firm mentioned earlier began its journey by reviewing existing processes and technologies, and uncovered a number of opportunities to improve database build and release timelines. Here are three opportunities related to UAT:
1. Improve the efficiency of edit check UAT
On average, their teams have 300 to 500 edit checks per study. The firm was double- and triple-testing each edit check across functional areas—essentially creating multiple, redundant layers of edit check verification. Time can be shaved from this process by re-defining which teams test what edit checks and when. For many low-value datapoints, the vendor and data management teams can test those edit checks with high quality results without involving other teams. In addition, the edit checks for other low-value datapoints never fire, which raised the question of whether it is worth the time and effort to create and UAT those edit checks within their legacy electronic data capture (EDC) system. They are now evaluating which edit checks should be tested by whom and where, as part of a risk-based approach to UAT.
Eliminating the review of low-value datapoints upfront has helped the company employ a timesaving, risk-based process to significantly increase process efficiency.
2. Eliminate UAT of data elements from previous studies
UAT is a necessary but time-consuming process. The company maintained an extensive standards library but would still need to perform UAT on 100% of the edit checks in each study because it couldn’t verify that nothing changed from the previously tested elements. However, after adopting a new EDC solution, the company receives reports that show precisely what is different between two studies. Standards within one study can now be validated once and re-used in another study without additional UAT.
The company is working closely with its quality team to vet this new process. Once it has been validated and incorporated into the standard operating procedures, the company will only conduct UAT on things that changed from the comparison study, further improving speed and efficiency. This process change will have a particularly high impact, as 90% of the company’s trials are in one therapeutic area, so re-use from its standards library is high.
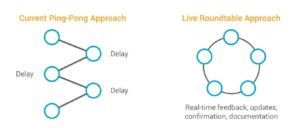
3. Move from ping-pong UAT to live UAT roundtables
Traditionally, UAT is a multiple-exchange, back-and-forth process between the sponsor and CRO. Internally, it can take many days to gather comments from all the stakeholders, and the CRO doesn’t start making updates until the slowest reviewer has finished. In total, these ping-pong exchanges can take four to six weeks.
The company replaced this cumbersome process with a live, roundtable-style approach to UAT that brings the vendor and sponsor teams together—either physically or virtually—for collaborative review. Both groups review and provide feedback in real time, and the system is updated concurrently. The equivalent of three rounds of UAT are now completed in two to three days.
Lock All Trial Data 30% Faster
The process of locking the EDC database confirms that all quality checks, cleaning, and query resolution are complete and prevents further changes to the data. It is also an opportunity for the data management team to directly impact clinical trial timelines and help speed medicines to patients. In order to reduce data lock times, the company emphasizes the importance of reviewing clinical trial data immediately—from the first patient screened—and continuously by all relevant stakeholders throughout the trial.
Since 2017, the company has also worked to eliminate any lag time or delay in receiving data, for example by building integrations into its primary labs and automating the data transfers. Combined, their efforts resulted in reduced data lock time on all its data by 31% from 22 days in 2017 to just 15 days today—less than half the industry average.
*A video detailing the company’s journey to improve clinical data management is available by clicking here.
References
1. Tufts Center for the Study of Drug Development. 2019. Drug development outsourcing outpaces internal spending. Impact Report 21(22). See report here.
2. Tufts Center for the Study of Drug Development. 2017. Industry research shows 97% of companies to increase use of real-world patient data for more accurate decision making. See full news here.
3. $1-$13 million a day at risk from product launch delays. 2014. The Pharma Letter. See the full article here.
4. Getz K. 2017. CISCRP and Tufts Center for the Study of Drug Development. Industry practices that will benefit by patient engagement. See full white paper here.

Richard Young (richard.young@veeva.com) is Vice President for Veeva Vault EDC and has 25 years of experience in life sciences, including operational experience in data management, eClinical solutions, and advanced clinical strategies.


